Welcome to the world of machine learning and data science, where powerful algorithms are changing how businesses operate!
Today, computers have gone from large machines to personal computers and now to the cloud. The possibilities are endless with advancing technology and a wide range of tools and techniques at our disposal.
Thanks to data science, data scientists can create powerful machines that analyze data using complex algorithms without spending a lot of money. They know how to use powerful tools to find valuable information buried in a sea of data. With their skills, they solve difficult problems, make accurate predictions, and help businesses make smart decisions.
In this blog, we’ll explore the top machine learning algorithms for 2023 and how they can help businesses make smarter decisions. Let’s dive in and discover the perfect algorithm for your business needs.
What are Machine Learning Algorithms?
Machine learning (ML) algorithms are computer programs designed to adapt and improve based on the data they process, with the goal of achieving specific outcomes. They are mathematical models that “learn” by analyzing data, often referred to as “training data.” Some common types of ML algorithms are linear regression and decision trees. Moreover, these algorithms find practical applications in various fields, such as fraud detection and personalized marketing in retail.
Why Do Machine Learning Algorithms Matter?
Today, machine learning is the most widely used and fastest-growing subset of artificial intelligence. It is commonly referred to as Software 2.0 because it is used to improve a wide range of computing concepts, including computer programming itself.
From smartphones to servers to watches and sensors, machine learning algorithms are embedded in nearly every type of device and hardware. Moreover, they are increasingly the foundation of many technological innovations and benefits, ranging from ridesharing to self-driving cars to spam filtering, among many others.

Now let’s delve into the essential machine learning algorithms for business applications in 2023, with a specific focus on the top 5.
Top 5 Machine Learning Algorithms For Business Applications in 2023
1. Regression
Regression is a fundamental machine learning algorithm that analyzes the relationship between variables and predicts numerical values based on historical data.
Simply put, regression is a way to figure out how things are related to each other. In addition, it helps predict numbers based on past data and can show patterns over time. Multiple linear regression and simple linear regression are the two most common types of regression.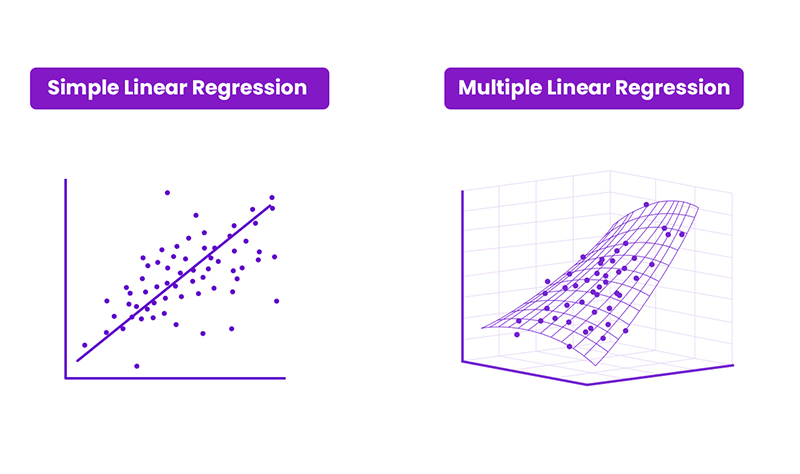
Let’s make it more simple: In an ice cream business, simple linear regression could help us see if there’s a connection between sales and the temperature of the storage. Moreover, multiple linear regression goes a bit deeper and looks at how things like temperature, pricing, flavours, and staff can all affect sales.
Although regression is easy to understand, it may not work for all situations. But when we have data over time, like sales information, regression can be really useful in predicting future values.
Business Use Case for Regression Algorithm
In this example, we’ll explore how a regression model can be applied in a restaurant business to achieve cost optimization. Also, by minimizing spoiled products and improving goods purchase planning, the model helps predict when and how many products should be bought based on their expiration dates. Hence, to create an effective model, historical data is essential, including:
- The number of dishes sold during previous periods (such as days or weeks)
- Information about holidays and other specific days
- Data on marketing campaigns
By adopting a regression model, the following benefits can be obtained:
- Explanation and prediction of numerical values using historical data
- Improved accuracy in purchase planning
This solution enables restaurateurs to make more informed and precise decisions, ultimately optimizing costs in their business operations.
2. Classification
Classification is a machine learning algorithm used to sort data into different categories. Moreover, it is helpful in various areas like spam filtering, document classification, and defect detection. In classification, we have classes or labels that we want to assign to the data.
There are different types of classification algorithms, such as binary, multiclass, and multilabel.
- Binary classification: In binary classification, we train the model to classify data into two categories. For example, classifying emails as spam or non-spam, or determining if someone has a lung disease or not.

- Multiclass classification: Multiclass classification involves training a model to classify data into more than two categories. For instance, identifying different animals like cats, dogs, and lizards.
- Multilabel classification: In multilabel classification, multiple labels can be assigned to different objects. For example, recognizing multiple animals in a single picture or tagging blog articles with relevant topics like “AI,” “ML techniques,” and “Healthcare.”
The models learn from labelled datasets to predict labels for new data, using patterns and features to make an accurate classification.
Business Use Case for Classification Algorithm
In this scenario, a helpdesk needs to assign tags to customer conversations for efficient navigation and topic grouping. Furthermore, an automated solution is necessary to streamline this process and minimize manual work.
The proposed business solution involves developing a multi-label classification model. Similarly, this model utilizes existing tagged customer data to automatically assign multiple tags to new conversations. As a result, call centre specialists can save time and focus on other high-priority tasks instead of manually assigning tags.
Moreover, by implementing this classification algorithm, the helpdesk can enhance productivity and improve the overall efficiency of customer support operations.
3. Clustering
Clustering is a method in machine learning that groups similar data together. It’s commonly used in business to segment customers and make personalized recommendations. Unlike classification, clustering doesn’t require labelled data. By identifying patterns and similarities, clustering helps reveal hidden insights in large datasets. Also, there are different algorithms available for tasks like anomaly detection and fraud detection. Overall, clustering enables businesses to understand their data better and make more informed decisions.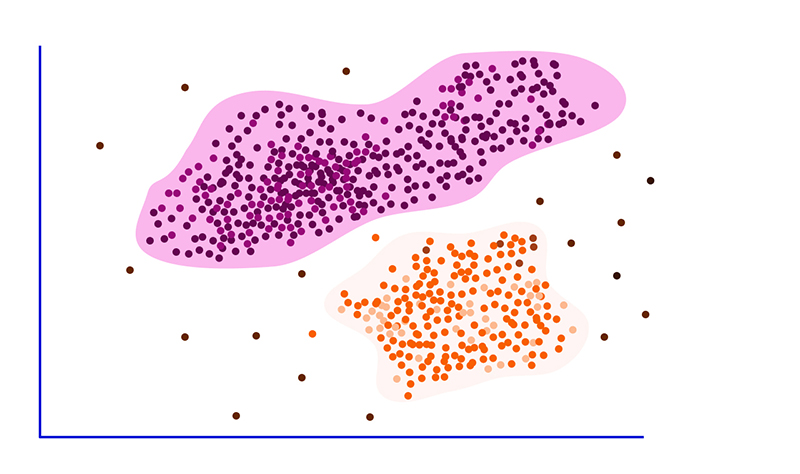
Business Use Case for Clustering Algorithm
Retail business can serve as an example here. In a retail business, the owner aims to analyze employee performance and identify those who are not working efficiently. To address this, a clustering model for anomaly detection is implemented. This model helps identify groups of employees whose behavior significantly differs from the majority. Moreover, by detecting these anomalies, the business can tackle performance issues, optimize productivity, and gain insights into operational cost efficiency.
4. Deep Learning
Deep learning (DL) is a field of AI that mimics human learning processes. It involves neural networks with multiple layers to solve complex problems. These algorithms simulate how our brains process information, learn words and recognize objects.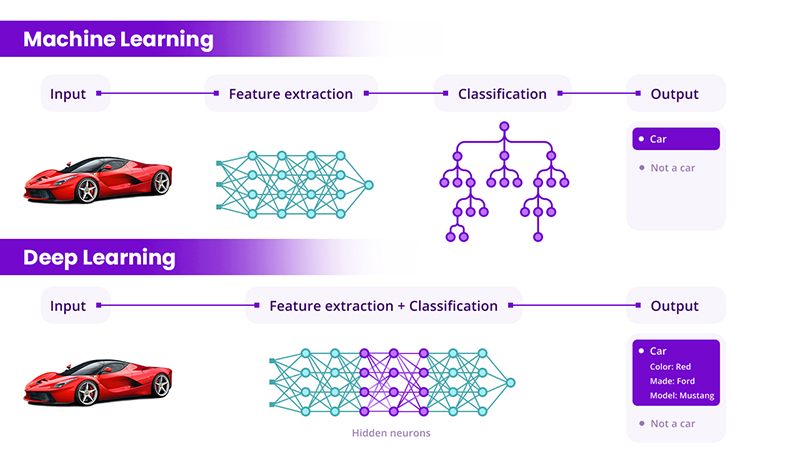
Deep learning is a subset of machine learning and differs from traditional AI/ML techniques. It doesn’t rely on predefined features in the data. Instead, it can work with raw data and automatically extract relevant features. Deep learning models thrive on large amounts of training data. The neural network layers pass information to each other, culminating in a decision at the output layer.
Business Use Case for Deep Learning
In a shoe business with customer support services via chats and phone, the owner aims to analyze service quality and customer satisfaction. The proposed business solution includes:
- Text summarization: Extracting relevant information from chat support text to analyze service quality.
- Speech-to-text models: Converting audio conversations to text for processing and analysis.
- Sentiment analysis models: Evaluating the tone of conversations to assess customer satisfaction (positive or negative dialogues).
By leveraging deep learning techniques, such as text summarization, speech-to-text models, and sentiment analysis, the business can gain insights into service quality and customer satisfaction levels. This enables the owner to make data-driven decisions and improve customer support operations.
5. Dimensionality Reduction
Dimensionality reduction techniques are used to simplify data by reducing the number of input features or variables. This is helpful because having too many features can lead to problems like overfitting, where the model doesn’t perform well on new data. By reducing dimensionality, we can avoid overfitting, save time during training, and improve the efficiency of the algorithm. Dimensionality reduction is a useful step in data preparation before modelling.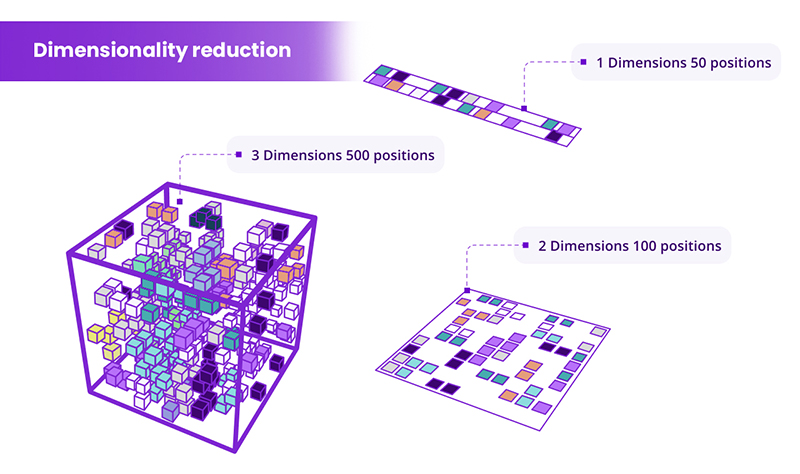
Business Use Case for Dimensionality Reduction
Let’s suppose a company with different types of sensors would like to make predictions based on historical data. However, the data is not very complete, which makes it hard to get accurate results with regular methods.
To solve this, they use a technique called dimensionality reduction. Moreover, it helps them choose the most important data and improve the accuracy of their predictions.
In addition, once they have the important data, they use regression or classification models to make predictions about specific things they’re interested in.
Also, by using dimensionality reduction, the company can analyze their sensor data better and make more accurate predictions.
Further, overcoming the challenge of selecting machine learning techniques, including regression and dimensionality reduction, is possible with available suggestions to guide you through the process.
How to Choose the Right ML Algorithm for Your Business App?
Machine learning can be classified into three types: supervised, unsupervised, and reinforcement learning.
- Supervised Learning: It uses labeled data for training. It helps predict values or categories.
- Unsupervised Learning: It finds patterns in data without using labeled information. It groups similar data or identifies structures.
- Reinforcement Learning: It learns by trying different actions and analyzing feedback to make better decisions.
These approaches offer flexibility for solving various business problems based on data characteristics.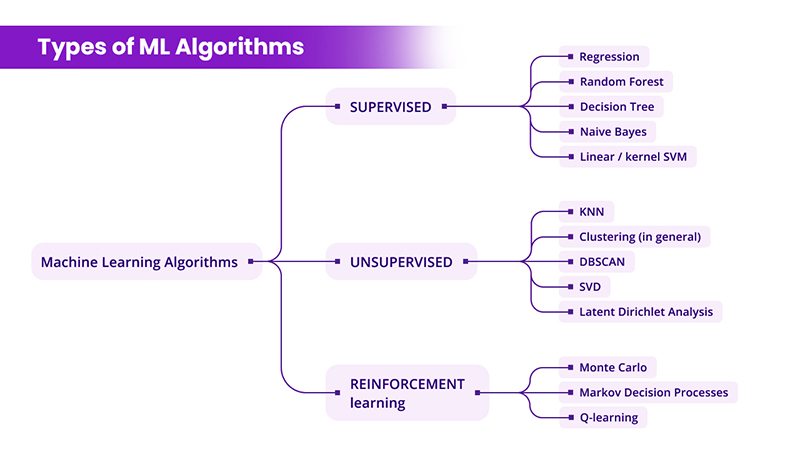
Frequently Asked Questions
What are the new machine learning techniques in 2023?
Automating natural speech understanding is a major trend in machine learning apps with intelligent voice assistants like Siri, Google, and Alexa.
What is the future of machine learning in business?
ML revolutionizes numerous industries, empowering informed decisions, innovative problem-solving, and delivering faster, accurate information.
Which machine learning algorithm is best for prediction?
Linear regression holds widespread recognition as a prominent algorithm in the fields of statistics and machine learning. It makes accurate predictions by minimizing errors, and prioritizing accuracy over explainability in predictive modelling.
Which language is best for machine learning in future?
Python programmers prefer TensorFlow and Scikit-learn for machine learning due to their versatility and effectiveness in various domains such as data science, sentiment analysis, and natural language processing.
Wrapping Up
After learning about the various ML algorithms, you can refer to the following step-by-step instructions for choosing the best algorithm for a given business application:
- Define the business problem and identify suitable algorithms for addressing it.
- Assess the available data, including its volume, characteristics, type, and behavior.
- Consider the optimal evaluation metric and speed requirements for the problem.
- Determine the appropriate number of features and parameters for the algorithm.
- Start with a baseline model and consider more advanced solutions only if necessary.
- Remember that high-quality data is more crucial than the specific algorithm used. Training time can often improve algorithm performance.
- If you require expert guidance or want to drive significant business change, consult experienced AI service provider for assistance in algorithm selection and implementation.
Looking for solutions? ThinkPalm’s AI Services can help! We are here to help you unlock the power of machine learning. Connect with our experts today and we will guide you in selecting the best algorithms tailored to your data and business goals. With our support, you can confidently make progress and achieve success. Trust us to navigate the path towards your business’s brighter future.

Author Bio
Vishnu Narayan is a dedicated content writer and a skilled copywriter working at ThinkPalm Technologies. More than a passionate writer, he is a tech enthusiast and an avid reader who seamlessly blends creativity with technical expertise. A wanderer at heart, he tries to roam the world with a heart that longs to watch more sunsets than Netflix!



